RAZČLENJEVALNIK
|
Če želite preizkusiti delovanje skladenjskega razčlenjevalnika, kliknite na sličico na levi ali na povezavo. Program lahko tudi prenesete na svoj računalnik in razčlenite svoje besedilo. |
KAJ JE SKLADENJSKI RAZČLENJEVALNIK?
Skladenjski razčlenjevalnik je računalniški program, s pomočjo katerega besedam v povedih lahko pripišemo skladenjska razmerja. Z jezikoslovnega vidika nam avtomatizirano skladenjsko razčlenjevanje na ogromnih besedilnih korpusih omogoča raziskavo temeljnih skladenjskih pojavov za slovenščino, kot se kažejo v dejanski rabi. Skladenjsko razčlenjevanje poleg tega predstavlja tudi enega temeljnih jezikovnotehnoloških postopkov obdelave besedil, ki omogoča in podpira kompleksnejše jezikovne tehnologije, kot so strojno prevajanje, luščenje informacij, govorno komuniciranje, avtomatsko povzemanje, odgovarjanje na vprašanja itd.
KAKŠEN MODEL RAZČLENJEVANJA SMO UPORABILI?
Za skladenjsko razčlenjevanje smo uporabili sistem odvisnostnih drevesnic, ki je bil razvit v okviru projekta Jezikoslovno označevanje slovenščine (JOS). Ta model v določeni meri sledi smernicam uveljavljenega skladenjskega razčlenjevanja, kakršnega poznamo iz tradicionalnih opisov slovenskega jezika, obenem pa upošteva temeljne ideje, ki jih zarisujejo že obstoječi sistemi avtomatiziranega odvisnostnega razčlenjevanja.
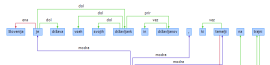
V uporabljenem odvisnostnem sistemu so skladenjski odnosi za vsako poved predstavljeni z drevesno strukturo, pri čemer vsaka povezava pripada enemu izmed desetih tipov povezav. V izogib terminološki zmedi smo se pri poimenovanju povezav zavestno odločali za imena, ki so drugačna od tistih, ki jih prinaša uveljavljeno slovensko jezikoslovje (npr. osebek, predmet, prislovno določilo …), saj skladenjska modela nista neposredno prekrivna. To pa seveda ne pomeni, da med seboj nista primerljiva, kar prikazujemo tudi v spodnji tabeli.
|
Skupina povezav |
Tip povezave |
Kaj povezuje |
|
Povezave prvega nivoja označujejo razmerja znotraj besednih zvez. |
dol |
Jedro in določilo besednih zvez. |
|
del |
Deli zloženega povedka. | |
|
prir |
Jedra v prirednih zvezah znotraj stavka. | |
|
vez |
Besede ali ločila v vezniški vlogi. | |
|
skup |
Nepolnopomenske besede,ki imajo zelo močno tendenco po sopojavljanju. | |
|
Povezave drugega nivoja označujejo stavčne člene. |
ena |
Osebek stavka. |
|
dve |
Predmet stavka. | |
|
tri |
Prislovno določilo lastnosti. | |
|
štiri |
Ostala prislovna določila. | |
|
Povezava tretjega nivoja se uporablja za povezovanje vseh ostalih struktur. |
modra |
Hierarhično najvišje pojavnice, skladenjsko manj predvidljive in oddaljene strukture, vrinki, ločila. |
Podrobnejša razlaga posameznih oznak in njihova umestitev z vidika tradicionalnih skladenjskih kategorij sta predstavljeni v specifikacijah za označevalce učnega korpusa.
KJE LAHKO PREIZKUSIM DELOVANJE RAZČLENJEVALNIKA?
Razčlenjevalnik lahko preizkusite na spletni strani razčlenjevalnik.slovenščina.eu. Spletni servis je namenjen predvsem razčlenjevanju krajših neoznačenih besedil, ki jim razčlenjevalnik pripiše oblikoskladenjske oznake (več o tem si lahko preberete v predstavitvi označevalnika) in skladenjske povezave. Za lažjo vizualizacijo pripisanih skladenjskih povezav smo razvili tudi poseben grafični vmesnik, ki oznake iz formata XML-TEI pretvori v barvito drevesnico. Za označevanje večje količine besedil ali za razčlenjevanje besedil z že pripisanimi oblikoskladenjskimi oznakami je na isti spletni strani za prenos na voljo tudi prosto dostopna programska oprema.
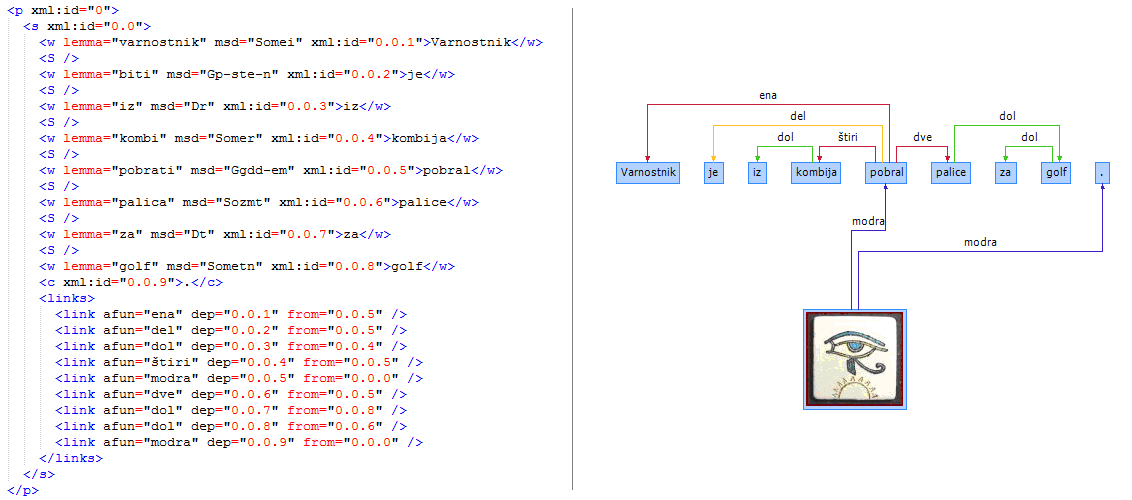
Primer skladenjsko razčlenjene povedi v formatu XML-TEI (levo) in njena vizualizacija (desno).
KAKO DELUJE PROGRAM DependencyParser?
Statistični razčlenjevalnik DependencyParser je osnovan na odprtokodnem razčlenjevalniku MSTParser, ki kot statistično metodo uporablja iskanje minimalnega vpetega drevesa v usmerjenih grafih. Navodila in datoteke za skladenjsko razčlenjevanje s programsko opremo DependencyParser najdete na spletni strani programa. Vsi vsebovani programi so delno izdelani v razvojnem okolju Microsoft Visual Studio 2010 in delno v okolju JAVA. Za svoje delovanje zato potrebujejo zagonsko okolje .NET Framework 4.0 in Java 1.6.
PROGRAM ZA VIZUALIZACIJO SKLADENJSKIH DREVESNIC
Za potrebe pregledovanja in urejanja skladenjskih drevesnic je bil razvit tudi program za vizualizacijo. Z njim je mogoče izvajati tudi razmeroma zahtevna iskanja po skladenjsko označenih besedilih v formatu XML. Program je prosto dostopen na spodnji povezavi, inštalirate ga lahko v okolju Windows tako, da ga razpakirate in kliknete na datoteko setup.exe. Če si želite ogledati že izdelan skladenjsko razčlenjen korpus, je na voljo tudi del učnega korpusa z 11.411 stavki, ki so ročno pregledani.
LICENCA IN PRENOS
Skladenjski razčlenjevalnik je prosto dostopen kot spletni servis in kot program, ki ga je mogoče namestiti na računalnik kot samostojno aplikacijo in z njim razčleniti večjo količino besedila. Razčlenjevalnik kot program je dostopen za prenos na spletni strani razčlenjevalnika. Licenca, pod katero je označevalnik dostopen za uporabo, je Apache License v2.0. Program za vizualizacijo skladenjskih drevesnic je dostopen pod enako licenco.
S klikom na povezavo lahko na računalnik prenesete:
1. program za vizualizacijo skladenjskih drevesnic.
2. skladenjsko označeni del učnega korpusa za ogled v programu za vizualizacijo. Velikost datoteke je 4,3MB.
AVTORJI
Razčlenjevalnik kot programska oprema: Jan Rupnik, Miha Grčar, Matjaž Juršič, Simon Krek, Kaja Dobrovoljc
SODELAVCI (po komponentah)
Predelava in razširitev programa MSTParser za slovenščino: Jan Rupnik
Oblikoslovni označevalnik Obeliks: Miha Grčar, Matjaž Juršič, Jan Rupnik, Simon Krek, Kaja Dobrovoljc
Program za vizualizacijo: Janez Brank
BIBLIOGRAFIJA
Kaja Dobrovoljc, Simon Krek, Jan Rupnik (2012): Skladenjski razčlenjevalnik za slovenščino. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Nina Ledinek, Tomaž Erjavec: Odvisnostno površinskoskladenjsko označevanje slovenščine: specifikacije in označeni korpusi. Zbornik Simpozija Obdobja: Infrastruktura slovenščine in slovenistike, Ljubljana, 2009.
R. McDonald, K. Lerman, and F. Pereira (2006): Multilingual Dependency Parsing with a Two-Stage Discriminative Parser. Tenth Conference on Computational Natural Language Learning (CoNLL-X).
