SPLETNI KONKORDANČNIKI
 |
 |
 |
Če želite preveriti delovanje konkordančnikov, kliknite na eno od sličic zgoraj.
KAJ JE SPLETNI KONKORDANČNIK?
Spletni konkordančnik je program, ki omogoča iskanje po obsežnih zbirkah besedil – korpusih – na spletu. Korpusni vmesnik, izdelan v okviru projekta Sporazumevanje v slovenskem jeziku, je prilagojen predvsem preprostejši (šolski) rabi, njegov glavni namen pa je ta, da uporabnikom omogoči intuitivno opazovanje rabe sodobnega slovenskega jezika, predvsem v korpusih Gigafida in Kres.
KAKO SMO PRIŠLI DO ZASNOVE VMESNIKA?
Vmesnik smo zasnovali z upoštevanjem tujih dobrih praks, ugotovitev korpusnih jezikoslovcev ter nenazadnje mnenj in želja dosedanjih korpusnih uporabnikov. V analizah in anketah, ki smo jih izvedli, se je izkazalo, da uporabniki številnih programskih možnosti ne uporabljajo oz. zanje sploh še niso slišali. Presenetilo nas je predvsem dejstvo, da več kot četrtina vprašanih ni vedela za možnost iskanja z uporabo besedne leme, dobra tretjina pa ne za možnost iskanja s pomočjo oblikoskladenjskih oznak. Rezultati vprašalnika so pokazali tudi, da velik del vprašanih – tudi tistih, ki korpus redno uporabljajo – v resnici nima pravega znanja za učinkovito ter ustrezno izrabo možnosti, ki jih ta vir ponuja. Ugotovili smo torej, da moramo v prvi vrsti do skrajnosti poenostaviti iskalne postopke, pregledovanje in nadaljnjo obdelavo korpusnih podatkov pa zasnovati tako, da bo uporabnikom intuitivna in enostavno razumljiva.
KAKŠNE SO OSNOVNE ZNAČILNOSTI VMESNIKA?
Vmesnik ne predvideva registracije in prijavljanja za delo, pred pričetkom rabe se prav tako ni potrebno prebijati skozi navodila za uporabo ali druge informacije o korpusu. Vpis iskalnega pogoja je prva aktivnost, ki se od uporabnika pričakuje, zato je na osnovni, vhodni strani vmesnika v ospredju predvsem iskalno okence. Iskanje po korpusu je v želji po intuitivnosti rabe primerljivo uporabi spletnih iskalnikov.
V iskalno okence preprosto vnesemo znakovni niz, ki ga v korpusu želimo poiskati. Iščemo lahko posamezne besede (npr. medved), besedne zveze (npr. polarni medved) oz. besedne nize, ki lahko vsebujejo tudi ločila (npr. kljub temu, da). Pri naprednem iskanju lahko uporabnik dodatno pogojuje, katere zadetke želi pridobiti, recimo glede na oblikoskladenjske lastnosti iskane besede ali glede na druge besede v besedilni okolici. Potrebno ni niti poznavanje posebnih postopkov, ampak uporabnik pogoje enega za drugim enostavno poklika v predpripravljenih vmesniških tabelah.
KATERE NOVOSTI SMO UVEDLI?
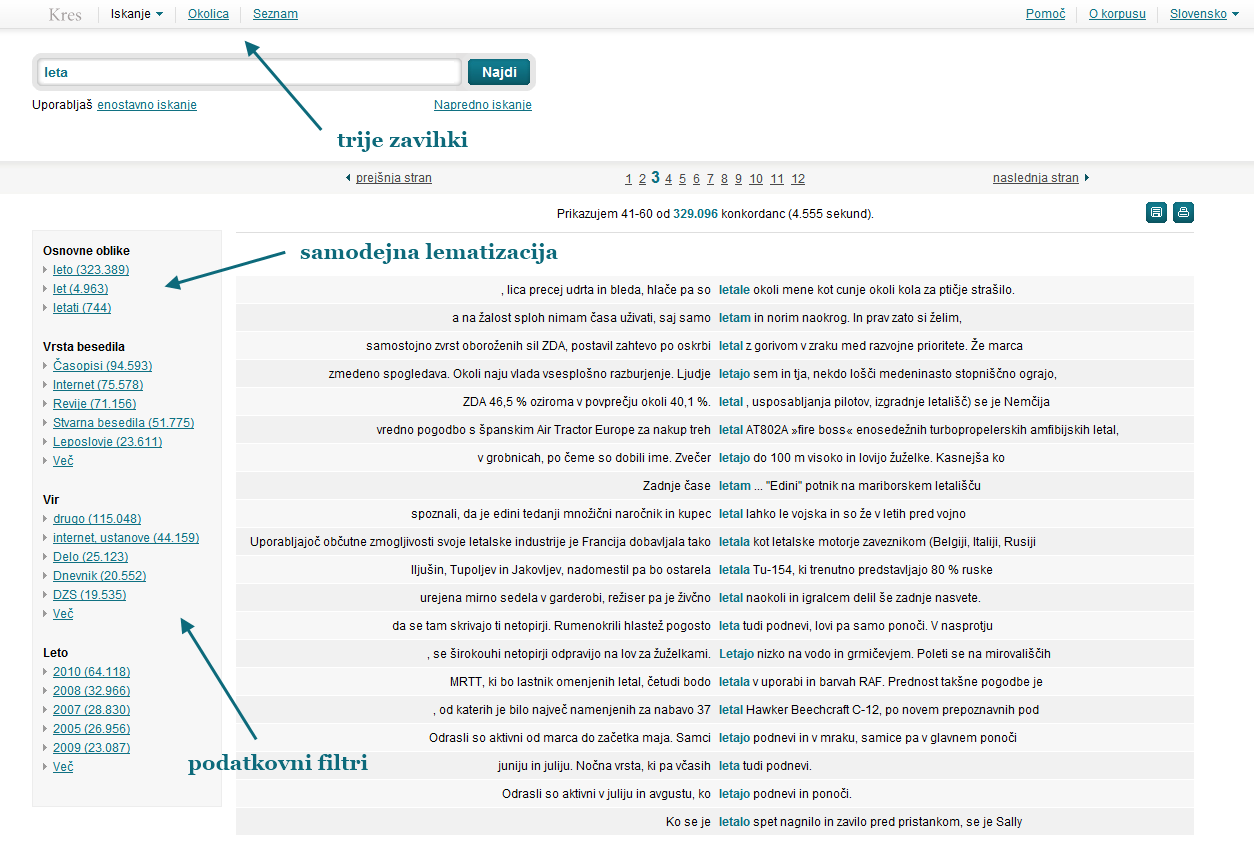
Velika razlika glede na prejšnje slovenske konkordančnike je vpeljava samodejne lematizacije iskalnega pogoja. Če je pri korpusu FidaPLUS uporabnik moral v iskalnem okencu opredeliti, da ga zanimajo vse oblike vnesene besede, mora po novem s pomočjo narekovajev opredeliti, kadar ga zanima ena sama, določena oblika. S stališča tipične uporabe slovenskih besedilnih korpusov je ta pot izdelave iskalnega pogoja precej bolj smiselna.
Pomembna novost je tudi uvedba t. i. podatkovnih filtrov. Filtri, ki se ob vsakem korpusnem iskanju avtomatsko pripravijo na osnovi korpusnih oznak, uporabniku na pregleden način pokažejo razpršenost iskanega jezikovnega pojava po besedilih. Uporabnik lahko v filtrih denimo vidi, kako pogosto se iskana beseda pojavlja glede na leto izida, vir besedila itd. Filtri obenem omogočajo, da uporabnik z enim samim klikom loči določen nabor podatkov iz celotne množice, npr. iz celotnega konkordančnega niza izbere samo tiste zadetke, ki izvirajo z interneta, ali iz celotnega nabora kolokatorjev izbere le tiste, ki so besednovrstno označeni kot glagoli.
Preglednost vmesnika smo dosegli tako, da smo uporabniku vedno ponudili samo tiste programske funkcije in povezave, ki jih pri določenem koraku svojega dela dejansko potrebuje. Na temeljni ravni se to odraža v delitvi vmesnika na tri dele (zavihke), vsak omogoča iskanje in pregledovanje druge vrste korpusnih podatkov: konkordančnih nizov, spiske kolokacij ali besednih seznamov. Vsak od treh delov vmesnika prinaša enako osnovno strukturo – možnost izvoza in tiskanja podatkov, podatkovne filtre, iskalno okence, zgodovino iskanj ipd. uporabnik najde vedno na istem mestu – obenem pa je v določenih točkah prilagojen specifikam obravnave jezikovnih podatkov, ki jih prinaša.
LASTNIŠTVO IN DOSTOPNOST
Konkordančniki so bili izdelani v okviru dveh projektov: konkordančnika za Gigafido in Kres v okviru projekta “Sporazumevanje v slovenskem jeziku”, konkordančnik za Gos pa v okviru projekta “Spletni konkordančnik za nacionalni govorni korpus slovenskega jezika”. Lastnik vmesnika za pisne korpuse (Gigafida in Kres) je Ministrstvo za izobraževanje, znanost in šport. Če vmesnik želite uporabiti za svoj korpus ali dobiti dodatne informacije, pišite na naslov info@slovenscina.eu.
AVTORJI
Konkordančnik za korpusa Gigafida in Kres: Rok Rejc, Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar
Konkordančnik za korpus Gos (projekt Spletni konkordančnik za nacionalni govorni korpus slovenskega jezika): Darinka Verdonik, Ana Zwitter Vitez, Rok Rejc, Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek
SODELAVCI (po nalogah in projektih)
Zasnova konkordančnika: Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar, Nataša Logar Berginc
Izdelava konkordančnika: Rok Rejc, Simon Rigač
Vodja projekta “Spletni konkordančnik za nacionalni govorni korpus slovenskega jezika”: Darinka Verdonik
Zasnova konkordančnika (izdelava prototipa, koordinacija): Simon Rigač
Sodelujoče ustanove pri zasnovi konkordančnika GOS:
- Fakulteta za elektrotehniko, računalništvo in informatiko, Univerza v Mariboru (prijavitelj)
- Amebis, d. o. o., Kamnik
- Filozofska fakulteta, Univerza v Ljubljani
- Trojina, zavod za uporabno slovenistiko
Izdelava konkordančnika: Rok Rejc, Simon Rigač
BIBLIOGRAFIJA
Iztok Kosem (2010): User-friendly concordancers for corpora of Slovene. Konferenca Slavicorp. Varšava, Poljska.
Iztok Kosem (2010): Something for teachers and something for learners: the design of a user-tailored concordancer for Slovene Corpora. Teaching and Language Corpora (TALC8) conference. Brno, Češka.
Zwitter Vitez, Ana, 2010: Kako in zakaj uporabljati govorni korpus slovenskega jezika. Predstavitev na konferenci Korpusi, več kot le statistika, Ljubljana, FDV.
Verdonik, Darinka, Zwitter Vitez, Ana, Romih, Miro, Krek, Simon, 2010: Konkordančnik za govorni korpus GOS. Erjavec, Tomaž, Žganec Gors, Jerneja (ur.): Zbornik Sedme konference Jezikovne tehnologije – IS 2010. Ljubljana: Institut Jožef Stefan. 12-15.
Verdonik, Darinka, 2011: Govorni korpus kot lektorjev priročnik. Krakar Vogel, Boža (ur.): Slavistika v regijah – Maribor: Zbornik Slavističnega društva Slovenije. Ljubljana: Zveza društev Slavistično društvo Slovenije. 171-173.
Verdonik, Darinka, Zwitter Vitez, Ana, 2011: Slovenski govorni korpus Gos. Ljubljana: Trojina, zavod za uporabno slovenistiko.
Zwitter Vitez, Ana, 2011: Korpus Gos in njegova uporaba v raziskovalne, didaktične in ljubiteljske namene. Kranjc, Simona (ur.): Meddisciplinarnost v slovenistiki – Obdobja 30. Ljubljana: Center za slovenščino kot drugi/tuji jezik. 559-564.
Špela Arhar Holdt, Iztok Kosem in Nataša Logar Berginc (2012): Izdelava korpusa Gigafida in njegovega spletnega vmesnika. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Nataša Logar Berginc, Miha Grčar, Marko Brakus, Tomaž Erjavec, Špela Arhar Holdt in Simon Krek (2012): Korpusi slovenskega jezika Gigafida, KRES, ccGigafida in ccKRES: gradnja, vsebina, uporaba. Ljubljana: Trojina, zavod za uporabno slovenistiko; Fakulteta za družbene vede.
