KRES

|
Če želite brskati po korpusu Kres v spletnem konkordančniku, kliknite na sličico na levi ali na povezavo. |
KAJ JE KRES?
Korpusi so elektronske zbirke avtentičnih besedil, nastale po vnaprej določenih merilih in z določenim ciljem ter opremljena z orodji, ki omogočajo večplastno iskanje jezikovnih podatkov. Korpus Kres je nastal v okviru projekta Sporazumevanje v slovenskem jeziku v letih 2008-2012, vsebuje pa skoraj 100 milijonov besed oz. natančno 99.831.145 besed.
ZAKAJ SMO ZGRADILI KRES?
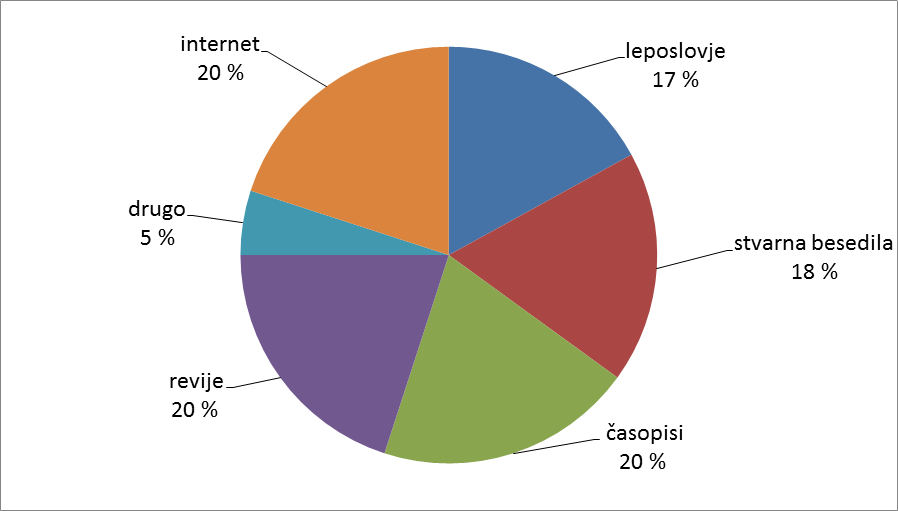
Kres je iz Gigafide vzorčeni uravnoteženi podkorpus. Za korpuse, ki predstavljajo celovito podobo nekega jezika, je ključno, da so veliki in besedilnovrstno pestri. Gigafida je tak, referenčni korpus, težko pa bi mu pripisali uravnoteženost, saj je v njem 77 % besed iz periodike (časopisi, revije) in npr. le dobrih 6 % besed iz knjig (leposlovje, stvarna besedila). Taka zgradba Gigafide je predvsem posledica tega, da smo vanjo vključili skoraj celotno FidoPLUS in vse, kar smo dobili na novo ter je avtorskopravno urejeno s pogodbo. Kot Gigafidin uravnoteženi podkorpus smo zato že predhodno načrtovali 100-milijonski Kres, katerega sestava je naslednja:
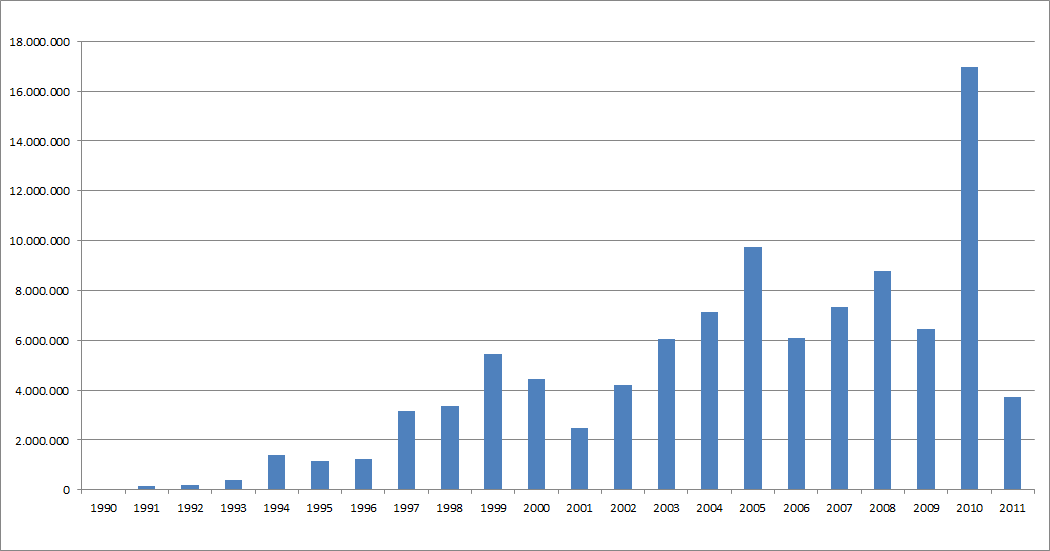
Kres vsebuje besedila, ki so izšla med letoma 1990 in 2011. Razlog za večje število besed, označenih z letnico 2010, je spletni del korpusa (20 %), ki je bil v celoti zbran in izdelan v tem letu.
KAKO SMO ZGRADILI KRES?
Enota vzorčenja besedil iz Gigafide za KRES ni bilo posamezno besedilo, pač pa naključni odstavek, s čimer smo omogočili čim boljšo zastopanost posameznih del. Če bi namreč v KRES dali celotna besedila, bi neko besedilo ali v celoti izpadlo ali pa bi bilo – posebej pri obsežnejših besedilih, kot so npr. celotni letniki časopisov, združeni v eno datoteko – v korpusu preveč prevladujoče. Osnova vzorčenja je bila vzorčna tabela z bibliografskimi podatki o besedilih in številom besed, ki smo jih želeli iz vsakega besedila dobiti za KRES.
Izbiro besedil za KRES v smislu kaj in koliko sta poleg vnaprej dogovorjenih deležev po taksonomiji usmerjala dva vira podatkov: Nacionalna raziskava branosti, v kateri so podatki o recepciji časopisov in revij, ter Merjenje obiskanosti spletnih strani MOSS, na podlagi katerega smo določili obseg besed s treh najbolj obiskanih novičarskih portalov (24ur.com, rtvslo.si, siol.net). Pri vseh drugih taksonomskih kategorijah smo sledili razmerjem v Gigafidi: iz leposlovja smo v KRES zajeli 71 % celote, iz stvarnih besedil 36 %, iz kategorije drugo 96 % zapisov sej Državnega zbora RS in besedil z RTV Slovenija, v okviru spletnih besedil pa še 12,5 % besed s strani podjetij ter 87,5 % besed s strani ustanov.
KOMU JE KRES NAMENJEN?
Enako kot Gigafida je Kres namenjen različnim uporabnikom: znanstvenikom in raziskovalcem, ki jih zanima sodobni slovenski jezik, učiteljem slovenščine v osnovnih in srednjih šolah, njihovim učencem, tistim, ki se slovenščine učijo kot drugega ali tujega jezika, pa tudi vsem drugim, ki se znajdejo pred jezikovno dilemo, povezano s sodobno slovenščino. Bolj kot Gigafida je Kres namenjen kakršnimkoli jeziko(slov)nim poizvedovanjem, ki imajo težnjo po merodajnosti, kolikor pač ta izhaja iz vzorca (korpusa), ki ima vnaprej premišljeno in znano ter utemeljeno uravnoteženo zgradbo. Rezultati poizvedb po tem korpusu so zaradi drugačne besedilnovrstne sestave seveda drugačni kot rezultati iskanja po Gigafidi.
Tudi vmesnik, v katerem je dostopen KRES, je isti kot vmesnik Gigafide, se pravi, da med drugim vsebuje uporabniško prijazne iskalne možnosti, samodejno lematizacijo iskalnega pogoja ter takojšen in samodejen prikaz podatkovnih filtrov.
KAJ POLEG BESEDIL ŠE VSEBUJE KRES?
Kres vsebuje tudi druge vrste informacij. Vsak posamezni dokument, ki jih je skupaj 21.456, vsebuje informacijo o viru (npr. Mladina, Delo, Dnevnik), letu nastanka, vrsti besedila (npr. leposlovje, revija), naslovu in avtorju, če je ta znan. Poleg tega je Kres jezikoslovno označen korpus, kar pomeni, da sta prav vsaki besedi v korpusu pripisana še dva podatka. Prvi je osnovna oblika besede ali lema (npr. jagode, jagodi, jagodam = jagoda), drugi je t.i. oblikoskladenjska oznaka. Ta oznaka opisuje, v katero besedno vrsto spada beseda (samostalnik, glagol, pridevnik itd.) in kakšne so njene lastnosti (npr. spol, število, sklon). Ker gre za ogromne količine besedil, je označevanje potekalo povsem avtomatsko s pomočjo statističnega označevalnika Obeliks, ki je bil ravno tako izdelan v okviru projekta Sporazumevanje v slovenskem jeziku. Delovanje označevalnika lahko preizkusite tudi na spletu.
LASTNIŠTVO IN DOSTOPNOST
Lastnik korpusa Kres je Ministrstvo za izobraževanje, znanost in šport. Korpus je prosto dostopen za uporabo v (različnih) spletnih vmesnikih, baza korpusa v tekstovni obliki (format XML) zaradi varovanja avtorskih pravic besedilodajalcev ni prosto dostopna. Če želite dobiti dostop do celotne baze v tekstovni obliki ali če želite vključiti korpus v svoj spletni vmesnik, pišite na naslov info@slovenscina.eu. Korpus ccKres, 9-odstotni del korpusa Kres, je prosto dostopen tudi v tekstovni obliki in ga najdete na strani s prostimi zbirkami.
KORPUS KRES KOT PODATKOVNA ZBIRKA
Avtorji: Nataša Logar Berginc, Simon Krek, Tomaž Erjavec, Miha Grčar, Peter Holozan
KONKORDANČNIK ZA KORPUS KRES
Avtorji: Rok Rejc, Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar
SODELAVCI (po nalogah)
Vodenje zbiranja besedil in specifikacija korpusa Kres: Nataša Logar Berginc
Zbiranje besedil: Simon Šuster, Matic Korošec, Teja Roglič, Mateja Grča, Urška Sančanin, Tamara Ambrožič, Mitja Knapič, Nataša Gliha Komac
Pretvorba besedil: Simon Šuster
Pajkanje spletnih besedil: Miha Grčar
Jezikoslovno označevanje: označevalnik Obeliks (Miha Grčar, Matjaž Juršič, Simon Krek, Kaja Dobrovoljc)
Shema XML, validacija s TEI in vzorčenje korpusa Kres: Tomaž Erjavec
Zasnova konkordančnika: Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar, Nataša Logar Berginc
Izdelava konkordančnika: Rok Rejc, Simon Rigač
BIBLIOGRAFIJA
Članki, monografije
Nataša Logar Berginc, Miha Grčar, Marko Brakus, Tomaž Erjavec, Špela Arhar Holdt in Simon Krek (2012): Korpusi slovenskega jezika Gigafida, KRES, ccGigafida in ccKRES: gradnja, vsebina, uporaba. Ljubljana: Trojina, zavod za uporabno slovenistiko; Fakulteta za družbene vede.
Špela Arhar Holdt, Iztok Kosem in Nataša Logar Berginc (2012): Izdelava korpusa Gigafida in njegovega spletnega vmesnika. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan. 16-21.
Tomaž Erjavec in Nataša Logar Berginc (2012): Referenčni korpusi slovenskega jezika (cc)Gigafida in (cc)KRES. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan. 57-62.
Nataša Logar Berginc in Simon Krek (2012): New Slovene corpora within the communication in Slovene project. Prace Filologiczne 63. 197-207.
Nataša Logar Berginc in Iztok Kosem (2011): Gigafida – the new corpus of modern Slovene: what is really in there? Slavicorp conference. Dubrovnik.
Nataša Logar Berginc in Simon Krek (2010): New Slovene corpora within the “Communication in Slovene” project. Slavicorp conference. Warsaw.
Nataša Logar Berginc in Simon Šuster (2009): Gradnja novega korpusa slovenščine. Jezik in slovstvo 54/3–4. 57–68.
Videolectures
Nataša Logar (2009): Korpus: niso ga samo besede.
