GIGAFIDA

|
Če želite brskati po korpusu Gigafida v spletnem konkordančniku, kliknite na sličico na levi ali na povezavo. |
KAJ JE GIGAFIDA?
Korpusi so elektronske zbirke avtentičnih besedil, nastale po vnaprej določenih merilih in z določenim ciljem ter opremljena z orodji, ki omogočajo večplastno iskanje jezikovnih podatkov. Korpus Gigafida je obsežna zbirka slovenskih besedil najrazličnejših zvrsti, od dnevnih časopisov, revij do knjižnih publikacij vseh vrst (leposlovje, učbeniki, stvarna literatura), spletnih besedil, prepisov parlamentarnih govorov in podobno, vsebuje pa skoraj 1,2 milijarde besed oz. natančneje 1.187.002.502 besedi.
ZAKAJ SMO ZGRADILI GIGAFIDO?
Gigafida je namenjena raziskovanju sodobnega slovenskega jezika na več ravneh. Tako po eni strani daje odgovore na posamezne sprotne poizvedbe, še pomembneje pa je, da daje podatke o celotni podobi slovenščine. Na ta način je danes skoraj edini razmeroma zanesljiv vir za izdelavo sodobnih slovarjev, slovnic in različnih jezikovnih priročnikov za slovenščino, uporablja pa se tudi v jezikovnih tehnologijah.
Ožje, v okviru projekta Sporazumevanje v slovenskem jeziku, je Gigafida izhodišče za prikaz realne podobe slovenskega jezika v pedagoškem slovničnem portalu, slogovnem priročniku in leksikalni bazi za slovenščino, in sicer tako v smislu iz korpusa pridobljenih podatkov ter njihovih interpretacij kot konkretnih zgledov.
KOMU JE GIGAFIDA NAMENJENA?
Z Gigafido želimo seznaniti ne le znanstvenike in raziskovalce v jezikoslovju, temveč tudi učitelje slovenščine v osnovnih in srednjih šolah, njihove učence, tiste, ki se slovenščine učijo kot drugega ali tujega jezika, pa tudi vse, ki gredo namesto na knjižno polico odgovor na svojo jezikovno zadrego raje iskat na svetovni splet. Široki množici različnih uporabnikov smo prilagodili tudi vmesnik, ki vsebuje med drugim uporabniško prijazne iskalne možnosti, samodejno lematizacijo iskalnega pogoja ter takojšen in samodejen prikaz podatkovnih filtrov.
KATERA BESEDILA VSEBUJE GIGAFIDA?
Gigafida vsebuje besedila, ki so izšla med letoma 1990 in 2011. Gre za tiskana besedila in za besedila, pridobljena s spletnih strani. Tiskana besedila so izšla bodisi kot knjige z leposlovno ali stvarno vsebino bodisi v periodični obliki kot revije ali časopisi. Besedila s spleta smo pridobivali z novičarskih portalov ter predstavitvenih strani večjih slovenskih podjetij in pomembnejših državnih, pedagoških, raziskovalnih, kulturnih ipd. ustanov. Delež pridobljenih besedil po številu besed v posamezni kategoriji prikazuje spodnja slika.
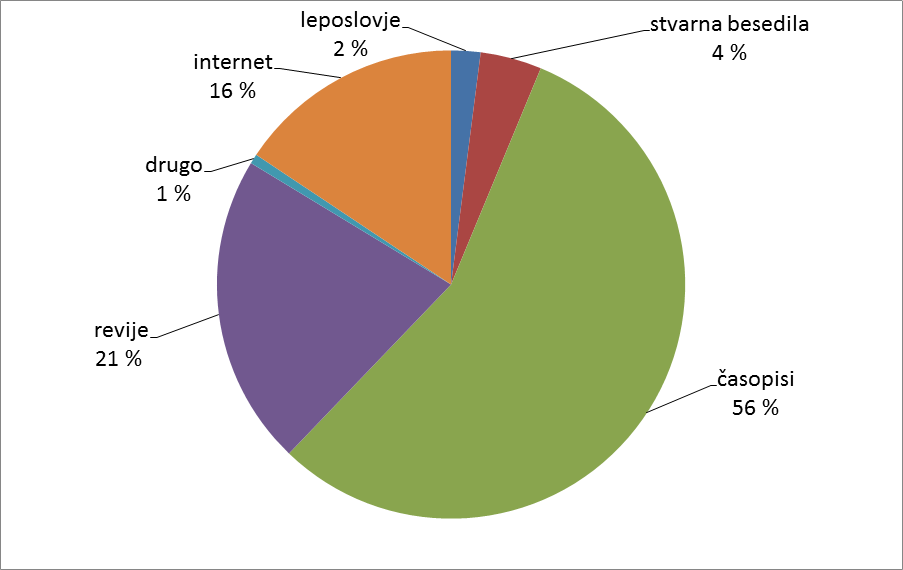
V Gigafido smo vključili skoraj celotni predhodni referenčni korpus slovenščine, tj. korpus FidaPLUS (2006), in vse gradivo, ki smo ga dobili na novo ter so zanj pogodbeno urejena avtorskopravna razmerja, medtem ko smo bolj uravnotežena razmerja med vrstami besedil že predhodno načrtovali in jih tudi uresničili v 100-milijonskem podkorpusu: KRES-u.
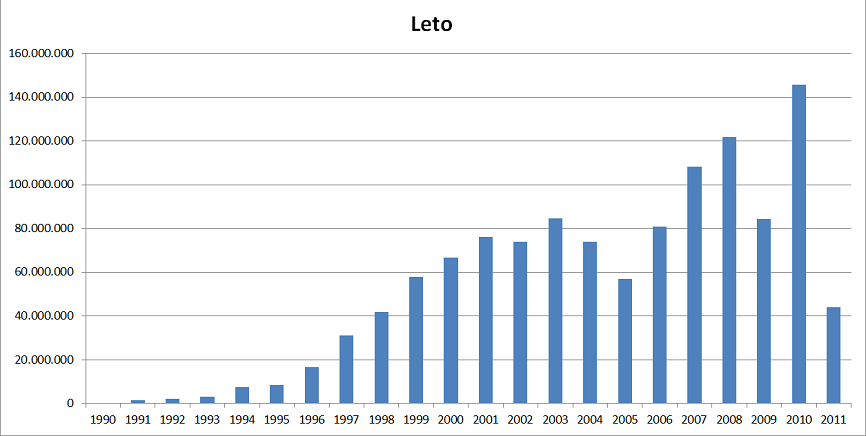
Število besed glede na leto izida, kot ga prikazuje spodnja slika, kaže dokaj stalno letno povečevanje količine gradiva.
KAJ POLEG BESEDIL ŠE VSEBUJE GIGAFIDA?
Gigafida vsebuje tudi druge vrste informacij. Vsak posamezni dokument, ki jih je skupaj 39.427, vsebuje informacijo o viru (npr. Mladina, Delo, Dnevnik), letu nastanka, vrsti besedila (npr. leposlovje, revija), naslovu in avtorju, če je ta znan. Poleg tega je Gigafida jezikoslovno označen korpus, kar pomeni, da sta prav vsaki besedi v korpusu pripisana še dva podatka. Prvi je osnovna oblika besede ali lema (npr. jagode, jagodi, jagodam = jagoda), drugi je t.i. oblikoskladenjska oznaka. Ta oznaka opisuje, v katero besedno vrsto spada beseda (samostalnik, glagol, pridevnik itd.) in kakšne so njene lastnosti (npr. spol, število, sklon). Ker gre za ogromne količine besedil, je označevanje potekalo povsem avtomatsko s pomočjo statističnega označevalnika Obeliks, ki je bil ravno tako izdelan v okviru projekta Sporazumevanje v slovenskem jeziku. Delovanje označevalnika lahko preizkusite tudi na spletu.
LASTNIŠTVO IN DOSTOPNOST
Lastnik korpusa Gigafida je Ministrstvo za izobraževanje, znanost in šport. Korpus je prosto dostopen za uporabo v (različnih) spletnih vmesnikih, baza korpusa v tekstovni obliki (format XML) zaradi varovanja avtorskih pravic besedilodajalcev ni prosto dostopna. Če želite dobiti dostop do celotne baze v tekstovni obliki ali če želite vključiti korpus v svoj spletni vmesnik, pišite na naslov info@slovenscina.eu. Korpus ccGigafida, 9-odstotni del korpusa Gigafida, je prosto dostopen tudi v tekstovni obliki in ga najdete na strani s prostimi zbirkami.
KORPUS GIGAFIDA KOT PODATKOVNA ZBIRKA
Avtorji: Nataša Logar Berginc, Simon Krek, Tomaž Erjavec, Miha Grčar, Peter Holozan, Simon Šuster
KONKORDANČNIK ZA KORPUS GIGAFIDA
Avtorji: Rok Rejc, Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar
SODELAVCI (po nalogah)
Vodenje zbiranja besedil: Nataša Logar Berginc
Zbiranje besedil: Simon Šuster, Matic Korošec, Teja Roglič, Mateja Grča, Urška Sančanin, Tamara Ambrožič, Mitja Knapič, Nataša Gliha Komac
Pretvorba besedil: Simon Šuster
Pajkanje spletnih besedil: Miha Grčar
Jezikoslovno označevanje: označevalnik Obeliks (Miha Grčar, Matjaž Juršič, Simon Krek, Kaja Dobrovoljc)
Shema XML, validacija s TEI in vzorčenje korpusa Kres: Tomaž Erjavec
Zasnova konkordančnika: Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar, Nataša Logar Berginc
Izdelava konkordančnika: Rok Rejc, Simon Rigač
BIBLIOGRAFIJA
Članki, monografije
Nataša Logar Berginc, Miha Grčar, Marko Brakus, Tomaž Erjavec, Špela Arhar Holdt in Simon Krek (2012): Korpusi slovenskega jezika Gigafida, KRES, ccGigafida in ccKRES: gradnja, vsebina, uporaba. Ljubljana: Trojina, zavod za uporabno slovenistiko; Fakulteta za družbene vede.
Špela Arhar Holdt, Iztok Kosem in Nataša Logar Berginc (2012): Izdelava korpusa Gigafida in njegovega spletnega vmesnika. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan. 16-21.
Tomaž Erjavec in Nataša Logar Berginc (2012): Referenčni korpusi slovenskega jezika (cc)Gigafida in (cc)KRES. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan. 57-62.
Nataša Logar Berginc in Simon Krek (2012): New Slovene corpora within the communication in Slovene project. Prace Filologiczne 63. 197-207.
Nataša Logar Berginc in Iztok Kosem (2011): Gigafida – the new corpus of modern Slovene: what is really in there? Slavicorp conference. Dubrovnik.
Nataša Logar Berginc in Simon Krek (2010): New Slovene corpora within the “Communication in Slovene” project. Slavicorp conference. Warsaw.
Nataša Logar Berginc in Simon Šuster (2009): Gradnja novega korpusa slovenščine. Jezik in slovstvo 54/3–4. 57–68.
Videolectures
Nataša Logar (2009): Korpus: niso ga samo besede.
